Building a TikTok Scraping Infrastructure on GCP and the Challenges Faced
We have built a batch to scrape TikTok on GCP. We will share the system design story of GCP construction and the challenges we faced during the construction.
Background
In 2020, the most downloaded app was TikTok, which surpassed Facebook.
https://gigazine.net/news/20210811-tiktok-overtakes-facebook/
I also use TikTok.
While surfing the internet, I found a library called tiktok-scraper on the cloudflare site. The idea of using this to collect information from TikTok was the trigger.
※ Scraping is based on private use. Also, let's consider the interval of scraping so as not to put a load on TikTok.
tiktok-scraper
https://www.npmjs.com/package/tiktok-scraper
Scrape and download useful information from TikTok. No login or password are required. This is not an official API support and etc. This is just a scraper that is using TikTok Web API to scrape media and related meta information.
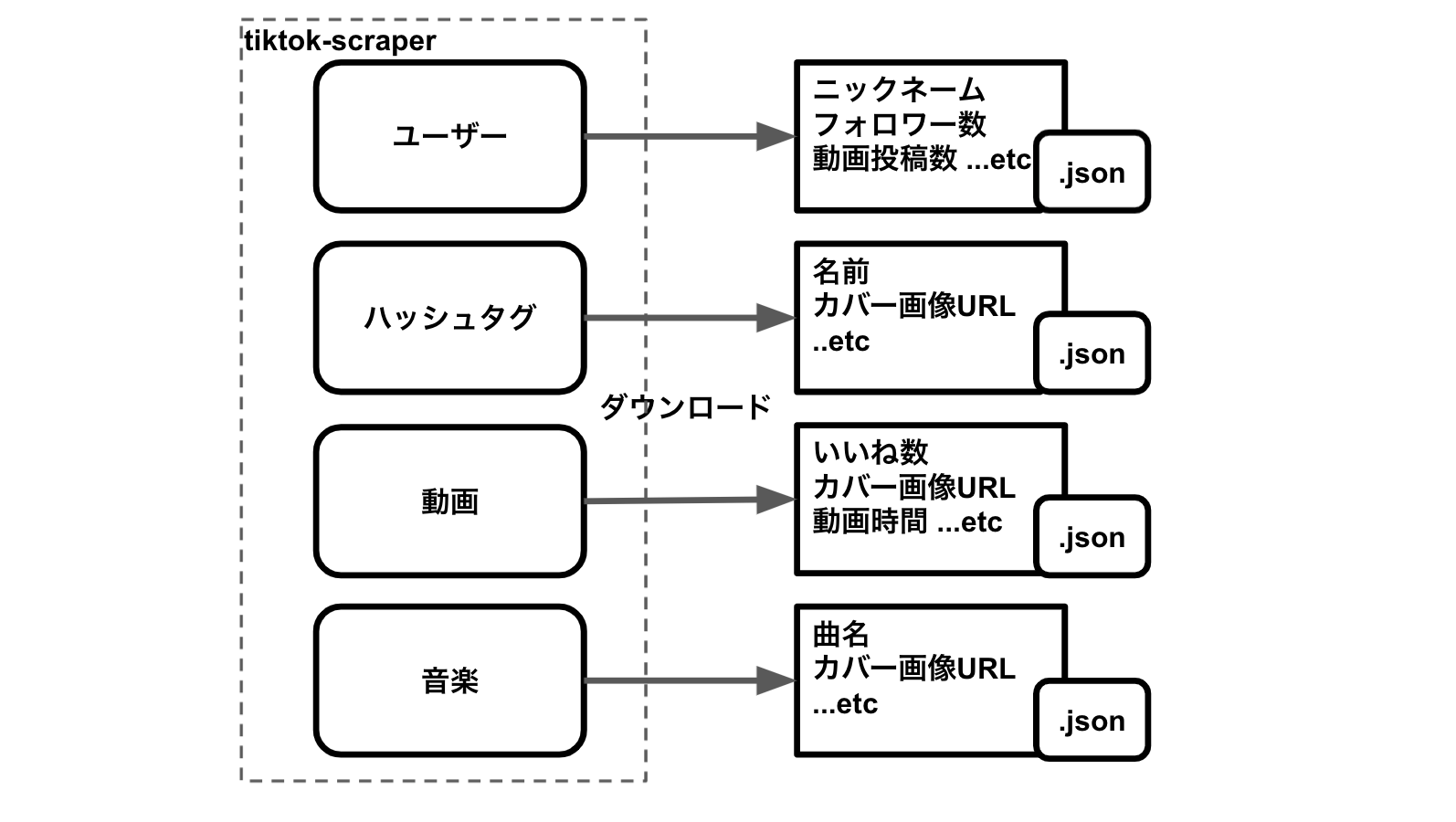
As mentioned above, it scrapes through TikTok's WebAPI. With the library, you can download specific TikTok videos, but you can also download TikTok videos in bulk from the following perspectives:
- User
- Hashtag
- Trend
- Music


In addition, you can also get meta-information (such as the number of followers and likes).
Inside, there are also links to TikTok CDN such as user images and video cover images. (https://p16-sign-va.tiktokcdn.com)
The link contains characters indicating the expiration date, and after a certain period of time, it becomes Access Denied.
The information that cannot be obtained is what requires login. For example, the users I follow. I wanted that information, so I somehow got it. (Details omitted) Using that user information, I thought about creating a batch to collect TikTok videos and metadata from the perspective of the user mentioned earlier.
※ If you hit the WebAPI too much, you will be added to TikTok's blacklist and access will be denied.
System Design
As for the environment to run the batch, I thought about building it on GCP, which I often use privately. I also thought about creating a web application to view the data collected by the batch, and decided to run it with Netlify and React.

Purpose
Collect TikTok videos and metadata of the users I follow.
I/O
- Input
- User information
- Output
- TikTok videos
- Metadata
GCP Resource Selection
- TikTok videos
- Save to Cloud Storage
- Metadata
- Save to Cloud SQL
- Computing resources
- Cloud Run
Design Diagram
The system design diagram of the actual GCP construction is as follows.
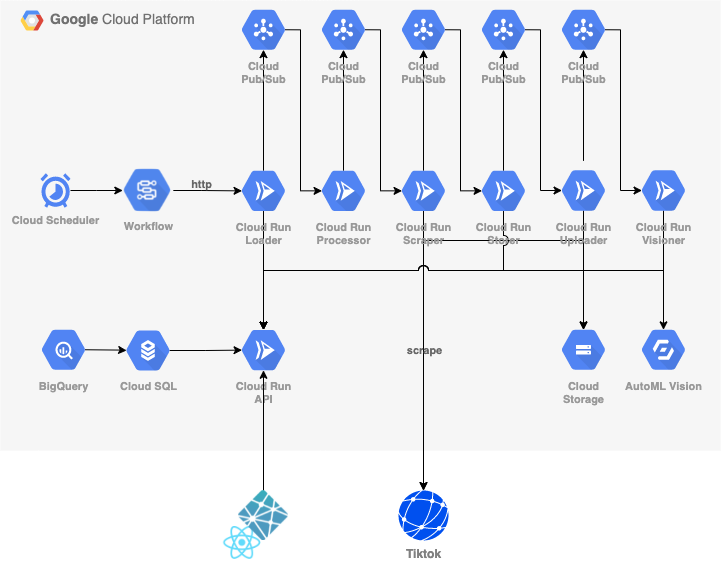
The purposes of the GCP resources are as follows.
| GCP Resource | Purpose |
|---|---|
| Cloud Scheduler | Manage batch launch schedule |
| Cloud Worlflows | Control batch workflow |
| Cloud Run | Process according to role |
| PubSub | Connect Cloud Run |
| Cloud Storage | Save videos |
| AutoML Vision | Label detection of video cover images |
| Cloud SQL | Manage all metadata |
The roles of each Cloud Run are as follows.
| Cloud Run Name | Role |
|---|---|
| Loader | Load user information |
| Processor | Perform a series of processes |
| Scraper | Scrape TikTok |
| Storer | Save the passed information |
| Uploader | Download videos and upload to Storage |
| Visioner | Extract label information through Vision API |
| API | Interface with Cloud SQL |
Things I Struggled With
Strict Limitations of Cloud Workflows
Initially, I thought of using Cloud Workflows for the integration of Cloud Run, without using PubSub. I thought it would be easier to control the workflow with the yaml of Cloud Workflows than to control the workflow with PubSub. Specifically, I was thinking of making an HTTP request to Cloud Run and calling the next Cloud Run according to the HTTP response.
However, Cloud Workflows has several limitations, as written on the following page.
https://cloud.google.com/workflows/quotas?hl=ja
What troubled me in particular was that the total memory of all variables is 64kb. If you adopt a configuration that holds the Body of the HTTP response in a variable, you have to consider its size. I tried to review several ways, but I couldn't finish it as I wanted and gave up. As a result, I decided to use PubSub to link Cloud Run. Cloud Workflows was used to kick off batches and send notifications.
It's Difficult to Move to ±2 Pages or More with Firestore's Page Cursor
Initially, I was using Firestore, which has a free tier for data storage in GCP. The reason was simply because Firestore was available as a GCP free tier.
Initially, I was writing a batch and a web app using Firestore. I prepared a View in the web app to list the TikTok videos collected by the batch.
As the number of TikTok videos to browse increased, I wanted pagination. So, when I looked up how to implement pagination with Firestore, I found the following document.
https://firebase.google.com/docs/firestore/query-data/query-cursors?hl=ja
Looking at this, it's easy to move ±1 page from the current position for pagination. As in the sample code in the document, all you have to do is use startAfter.
var first = db.collection("cities").orderBy("population").limit(25);
return first.get().then((documentSnapshots) => {
// Get the last visible document
var lastVisible = documentSnapshots.docs[documentSnapshots.docs.length - 1];
console.log("last", lastVisible);
// Construct a new query starting at this document,
// get the next 25 cities.
var next = db
.collection("cities")
.orderBy("population")
.startAfter(lastVisible)
.limit(25);
});
But what should you do if you want to move to ±2 pages or more from the current position? In the above sample code, should you copy and paste first to generate a second variable? Rather, I would like an offset method. However, I found the following document and decided to give up.
https://firebase.google.com/docs/firestore/best-practices?hl=ja
Do not use offsets. Instead, use cursors. When you use an offset, the skipped documents are not returned to your application, but they are still retrieved internally. The skipped documents affect the latency of your queries, and the read operations required to retrieve such documents are billable.
So, you are recommended to use query cursors.
A possible solution might be to have a field indicating the order. For example, if you have a field called order and data incremented by 1,2,3, you might be able to clear it. The argument for startAfter can include not only the document object but also the variables of the fields specified in the orderBy clause.
var next = db.collection("cities").orderBy("order").startAfter(50).limit(25);
With this, if you display 25 pieces of data per page, you can get the 3rd page (51~75). (startAfter does not include the starting point)
https://cloud.google.com/nodejs/docs/reference/firestore/latest/firestore/query
After all, I, who was more accustomed to the design of RDB than the document-based design, thought that Cloud SQL was easier to handle than Firestore. So, I decided to switch the data storage from Firestore to Cloud SQL. The modification itself was easy because the roles of Cloud Run were clearly separated, and I only had to rewrite some of the processes.
Eventarc's Resource Selection is Insufficient
We use Eventarc for the integration of Cloud Run and PubSub.
In October last year, we announced a new event feature, Eventarc, which can send events from over 60 Google Cloud sources to Cloud Run. Eventarc reads audit logs from various sources and sends them as CloudEvents format events to Cloud Run services. It can also read events from the Pub/Sub topics of custom applications.
I was considering designing with the Object.create of Cloud Storage as the source of this Eventarc. However, there are only two options for filtering that event.
https://cloud.google.com/blog/ja/products/serverless/demystifying-event-filters-eventarc
As of the time of writing (August 2021), the following two are possible.
- All resource
- Specific resource
All resource triggers the Object.create event in all Cloud Storage buckets.
Specific resource triggers only when a specific Object name is created.
What I wanted was filtering by regular expressions of Specific resource, limiting under any bucket or folder, etc.
For example, in the form of gs://bucket/folder/*.json. Currently, you can only do gs://bucket/folder/A.json.
This time, I made it trigger only with the event of PubSub.
If CloudRun Triggered by PubSub Returns HTTP Response 500, PubSub is Retried
In Cloud Run, if there is a 5XX series error, PubSub will be retried.
https://cloud.google.com/pubsub/docs/admin?hl=ja#using_retry_policies
If PubSub is executed many times, the computing resources of Cloud Run will continue to be consumed. Then, you will be charged, so you need to take measures.
Cloud Workflows Processing Cannot Be Customized Much
Cloud Workflows is just for workflow management. It is better to just connect the tasks of the workflow without using basic variable processing. The following document is the standard function that can be used with Cloud Workflows.
https://cloud.google.com/workflows/docs/reference/stdlib/overview
The function to parallelize the tasks of the workflow is still experimental, so it seems that it cannot be used in the production environment.
https://cloud.google.com/workflows/docs/reference/stdlib/experimental.executions/map
In Conclusion
Although the system design has changed frequently, we have been able to collect the desired TikTok videos and metadata. Even if there are changes, by keeping the roles as small as possible, we can respond flexibly to changes. Also, by actually operating it, there are points that can be noticed, so it is important to shorten the feedback cycle.
There is still room for improvement. We have been collecting information from the perspective of user information, but we would like to be able to obtain it from trends and hashtags as well. Also, by creating user RSS, we are thinking of trying to save money.

If it was helpful, support me with a ☕!
Share
Related tags
- My First Mobile App Development Attempt and Why I Gave Up
- Things I learned when I started using React at work
- Developing an oEmbed component with WebComponents and what I learned
- Thoughts on Using Ruby on Rails in Business
- Knowing the History Before Learning React
- Writing about what I learned from being infected with the Omicron variant
- Learning How Browsers Work
- It's become harder to "ask casually" since remote work started
- What I, an engineer in my late 20s, need to learn from now on
- Everything you need to know about Micro Frontends
- Introducing a Tool for Bulk Updating Account Images and What I Learned
- Everything I Learned About Micro Frontends
- Cotlin is a Tool for Collecting Links on Twitter, Discover Presentations from Around the World
- Why the Combination of FetchAll and RedirectURL in Google Apps Script is Bad
- I tried creating rMinc, a service that registers GMail to GCalendar
- I Tried Making a One-Frame Comic Search Service Tiqav2 (Algolia + Cloudinary + Google Cloud Vision API)
- Sharing All Experiences of First-time Writing at Techbook Fest 7
- Created an App to Consistently Record and Visualize Data in a Free Format
- Developing "Bochi-Bochi", an App to Easily Find Cheap Ingredients
- What I Learned from Refreshing My Blog Page with Qwik
- Introducing AI Ghostwriter - A Tool to Improve Writing Efficiency
- Development of Stable Diffusion API
- Defining Fragments Composed in Micro Frontends as Web Components and Sharing them with Module Federation
- Created OEmbed and OGP WebComponents for use on my blog site
- Things I Learned from Developing Chrome Extensions (Manifest V3)
- If you're writing in Markdown, Rocket, an SSG that uses WebComponents, is recommended!
- Refreshing Silverbirder's Portfolio Page (v2)
- I Made an API That Only Returns Google Account Images
- Micro Frontends on the Client Side (ES Module)
- Micro Frontends with Zalando tailor (LitElement & etcetera)
- Micro Frontends with SSR in Ara-Framework
- Created a GAS Library, zoom-meeting-creator, to Automatically Generate Zoom Meetings
- Introducing a Tool for Bulk Updating Account Images and What I Learned
- Cotlin is a Tool for Collecting Links on Twitter, Discover Presentations from Around the World
- I tried creating rMinc, a service that registers GMail to GCalendar
- I Tried Making a One-Frame Comic Search Service Tiqav2 (Algolia + Cloudinary + Google Cloud Vision API)